Software Is Eating the World (But Actually This Time)
Part of the AI Systems topic guide.
Coding was just the first workload, and almost everyone is underestimating how much inference demand will grow.
Software Ate the Interfaces. Now It's Eating the Work.
In 2011, software ate the world. At least that's what Marc Andreessen told us. But if that's true, then why does the Bay Area still exist? If software really ate everything, wouldn't we all have moved to New York or Miami by now?
Well, let's look at what software actually ate: banks got apps, retail got websites, hospitals got EHR systems, and taxis got dispatched with a few taps instead of a phone call at 2am when you maybe don't remember exactly where you are.
Software ate the interfaces, but the actual work? That mostly stayed human.
A customer calls about a billing dispute and software routes the call, pulls up the account screen, and then logs the resolution afterward. But here a person is still the one listening, figuring out whether the refund policy applies here, deciding what to do, and actually talking to the customer. A loan officer reviewing an application gets the credit score surfaced by software and the documents pulled up on screen, but they're the one reading those documents and making the judgment call. For 15 years, software has been really good at the plumbing while humans kept doing the actual work.
Now, AI can actually do the work! A customer service call is becoming an agent loop where the system handles speech recognition, looks up the account via API, pulls the relevant policy, reasons about whether the customer qualifies, triggers the refund, and responds with text-to-speech. An insurance claim is becoming document intake followed by coverage checks, fraud flags, reserve calculations, and settlement workflows, all running as code. A coding task is already 30 rounds of reading files, editing code, running tests, and revising with no human involved at all.
Each of those workflows is literally a piece of software executing tool calls in a loop. If you're an inference provider looking at your logs, a customer service agent resolving a billing dispute and a coding agent fixing a bug look like the same thing. They're both code.
So software is eating the world again, and this time inference is actually eating the work. The workloads getting eaten are the ones that are really just state transitions and exception handling wearing a human costume: support calls, insurance claims, loan processing, healthcare admin, legal analysis. Each one burns thousands of tokens per step across dozens of steps, often with multiple models running simultaneously. The total inference market is already processing tens of trillions of tokens per day, and it's growing multiplicatively: more users, more workflows falling into code, and more tokens per task as models get more capable.
Which Workloads Get Eaten
A workload gets absorbed by code when it's really just state transitions plus exception handling. The person doing the job might have a title like "claims adjuster" or "loan processor" or "revenue cycle specialist," but if you watch what they actually do all day, it's: look at input, check it against some set of rules, decide what bucket it goes in, take an action, handle the weird cases, move to the next one. If you can capture the input as text or voice or documents, the intermediate state lives in a database, and the output is something like "update this record" or "send this message" or "trigger this API call," then the whole thing can and will run as an agent loop.
There's one more condition that determines how deep the loop can go: verification. In coding, the agent can loop autonomously for 30 or more steps because verification is instant and free. Either the tests pass or they don't.
In domains like drug discovery, where real validation requires a wet lab that takes weeks / months, or robotics where the sim-to-real gap is still the hard part, the agent's loop hits a wall. These domains will use more inference over time, but there's a ceiling on how long the loop can spin before it has to wait for the physical world to catch up.
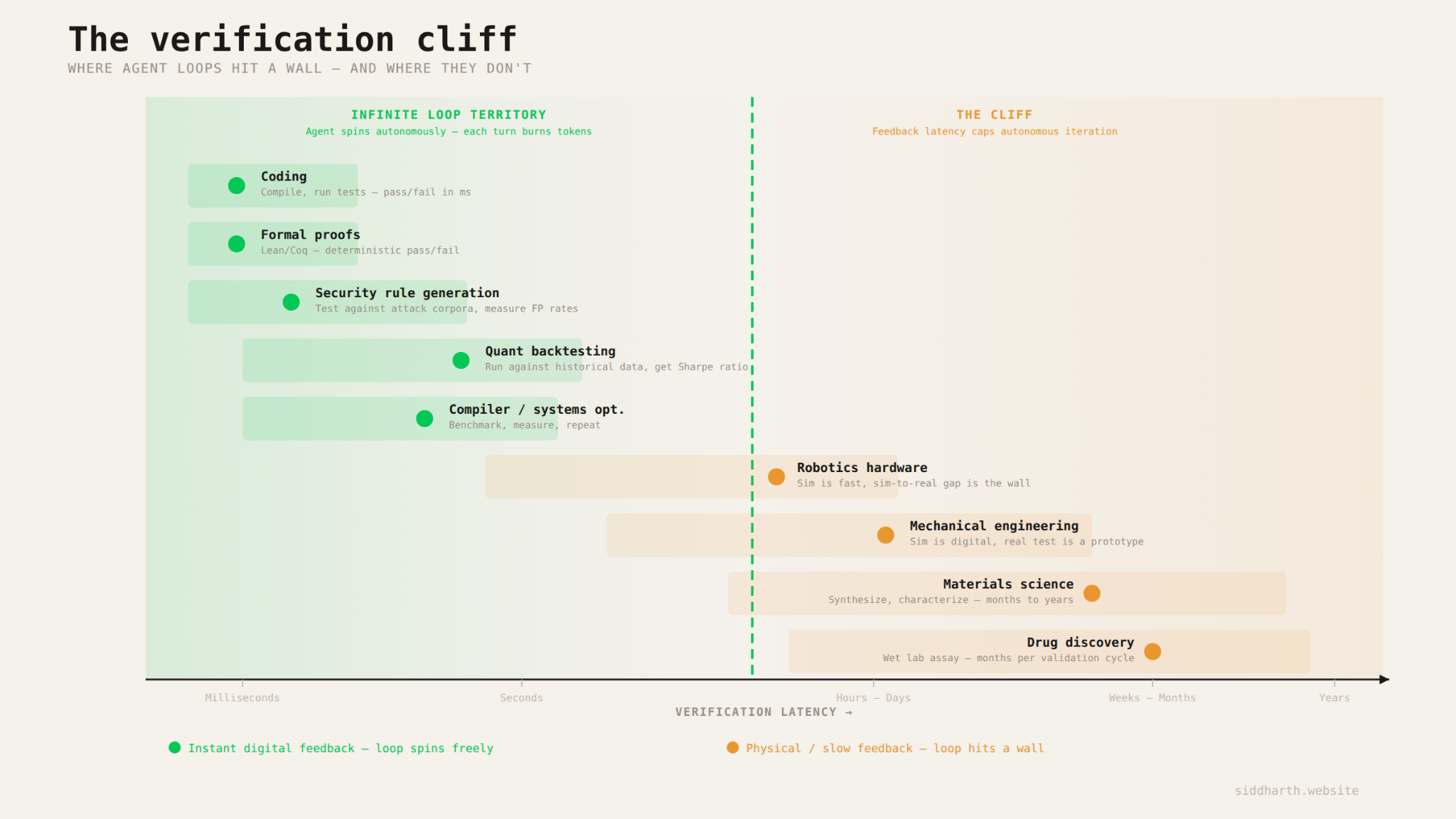
When a support agent resolves a ticket, the check is "did the API call succeed? did the record update?" or even "is the user satisfied with the response?". When a lending agent processes an application, the check is "does this document match the requirements? Did the compliance check pass?"
I think most people dramatically underestimate how much inference these converted workflows actually consume, because they're picturing one model, one call, one response, and some hallucinations along the way, but the reality is very different.
Take a voice support agent handling something simple but real, like rescheduling a medical appointment. To the customer, it feels like one conversation. Under the hood, it is a small autonomous system running continuously. As the caller speaks, a speech recognition model transcribes audio in real time. An orchestration model then reasons over the transcript, pulls the patient record, checks scheduling constraints, looks up provider availability, decides what to ask next, and calls the relevant tools. Once it has enough information, it synthesizes the result into a response, and a text-to-speech model turns that back into natural audio. In parallel, other models may be monitoring sentiment, checking compliance, or deciding whether the call should be escalated.
The system is doing all the work itself: listening, retrieving, deciding, tool-calling, verifying, and responding in a loop. An 8 minute call might contain only ~3k tokens of raw transcript, but the orchestration layer can easily consume ~40k tokens once you account for repeated reasoning over the growing conversation, retrieved context, and tool outputs, on top of continuous ASR and TTS inference running for the duration of the call. "One AI phone call" is really a multi-model inference stack operating continuously.
What's Still Emerging
The categories above already have production deployments, real usage, and workflows that have clearly been subsumed by code, but there is a second tier of markets where the same dynamic is starting to show up, just earlier in the curve.
Legal is a good example. The first wave of legal AI mostly sat at the search layer: find the relevant case, surface a risky clause, summarize a contract. Very useful, but relatively shallow from an inference perspective. The agentic work emerging now is much heavier. Imagine an M&A diligence agent reading the full data room, cross checking the purchase agreement against disclosure schedules and diligence materials, surfacing inconsistencies, drafting an issues memo with citations, and proposing redlines. This new legal agent is a long-running workflow operating over a massive corpus and producing real work product that a junior lawyer would otherwise spend days assembling. The shift is from helping a human find information to doing the analysis itself, which pushes the task from a few lightweight retrieval calls into a deep, multi-step loop.
Finance, accounting, supply chain, government casework, and procurement all have similar shape: lots of documents, lots of exceptions, lots of intermediate decisions, and more verification than people realize. These are the categories worth watching most closely over the next couple of years, because they sit right on the edge of model capability. As task horizons keep extending, more and more of this middle band will fall into code.
The Token Ladder
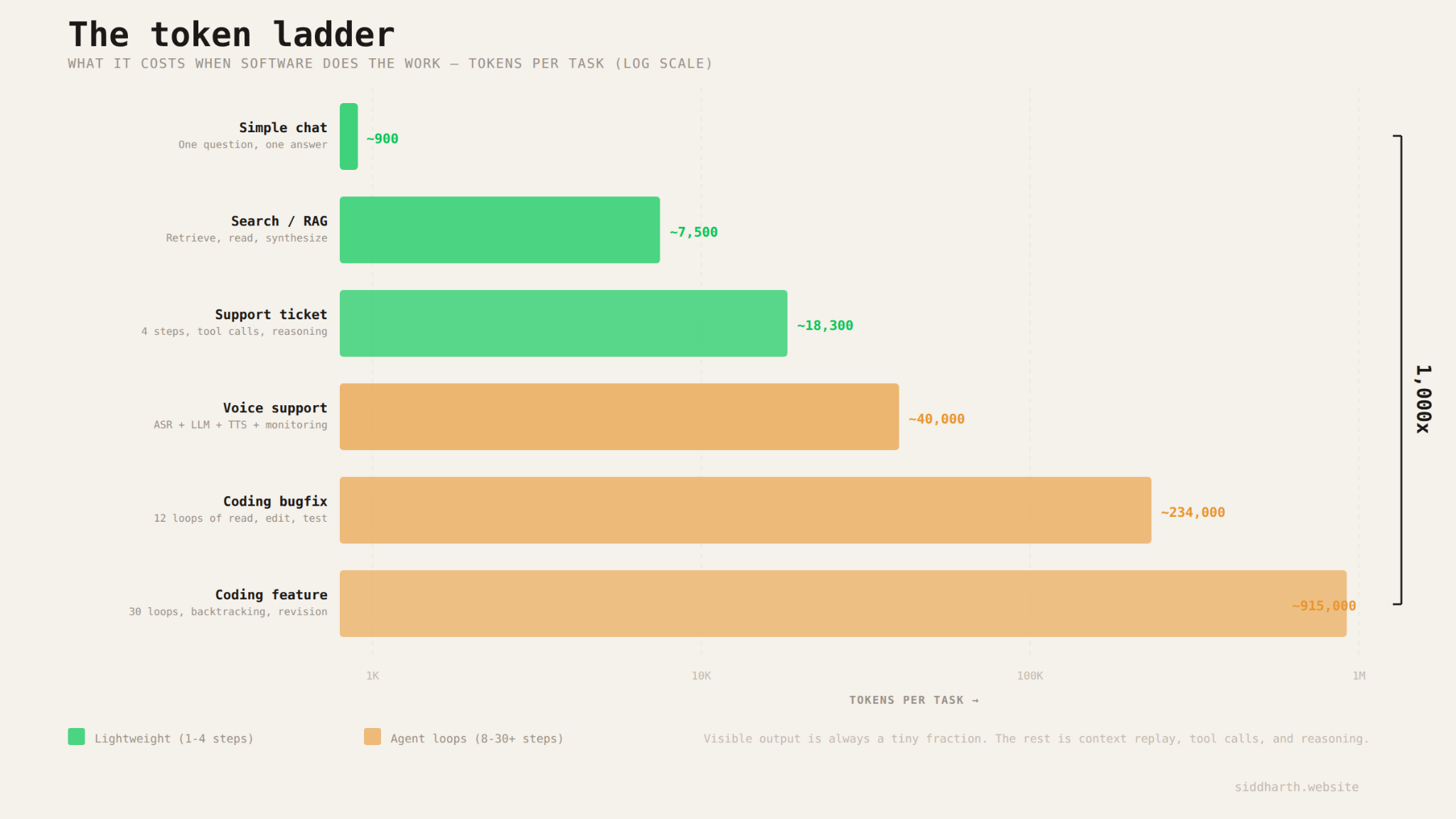
Open Claude Code on a real codebase and ask to fix a bug like: "there's a race condition in the auth flow that only appears under significant load". Before it does anything useful, the agent reads: relevant source files, tests, config, maybe some logs. That can easily mean ~60k tokens of context up front.
Then it enters the loop. It reads the failing test, inspects the auth module, forms a hypothesis, edits the locking logic, runs the tests on the new code, gets a new error (which is progress!), revises the hypothesis, and tries again. Sometimes the fix even breaks something upstream and the agent has to go reread a dependency it touched earlier. It does this over and over: read, edit, run, inspect, revise. After 30 iterations, the tests pass, the diff gets cleaned up, and the suite runs one final time.
That's three minutes of wall clock time and you may have burned ~900k tokens.
The striking thing is that the visible output is tiny. Maybe 500 tokens of actual code + an explanation. The other ~899,500 tokens are the machinery of the loop: replaying accumulated context, ingesting fresh tool output, reasoning about what to try next, and carrying forward all the history needed to stay coherent. The answer is small. The work is expensive.
Compare that to the pre-agentic version of the same model answering a straightforward question like: "What's the difference between optimistic and pessimistic locking?" That might take ~900 tokens total.
Agentic loops can increase inference demand by roughly three orders of magnitude. I think of it as a token ladder, and every task in the economy sits somewhere on it.
At the bottom is plain chat: one question, one response, no tools, maybe ~900 tokens.
One rung up is retrieval: the model searches a few documents, reads them, and writes a synthesis. Now you're closer to ~7,500 tokens. Most of the spend is not the answer itself, but the model reading and replaying retrieved context.
Then comes support. A basic FAQ bot can stay relatively light. But an agentic support system that checks your account, retrieves the relevant policy, reasons about eligibility, and actually takes action is much heavier. Same surface interaction, very different inference profile.
And then there is coding, which lives near the top of the ladder. A bounded bugfix can run into the hundreds of thousands of tokens. A real debugging or feature session can run close to a million. Anthropic's Claude Code docs say an active developer can burn about $13 a day in inference, which translates to roughly 1.5 to 3 million tokens per day depending on model mix and caching. A few serious coding tasks can consume more inference than a thousand chat conversations.
The pattern underneath this is simple:
tokens per task = initial context + (number of steps × tokens per step)
At the bottom of the ladder, there is one step, almost no context, and no tools. At the top, there are dozens of steps. Each step replays a growing history, pulls in fresh tool output, reasons over it, and emits only a small amount of visible work. That is why the rungs are so far apart.
Why the Ladder Keeps Getting Taller
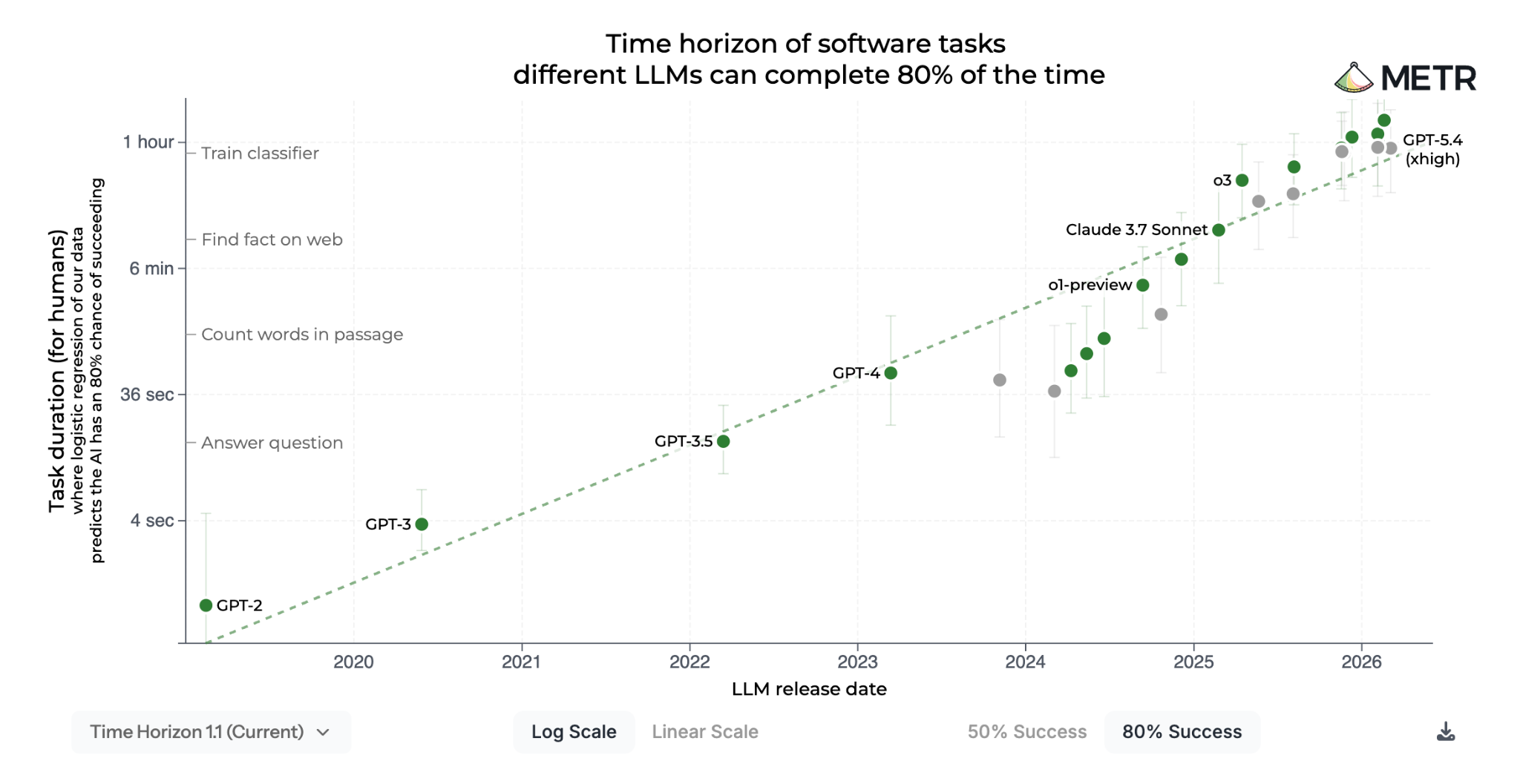
METR (creators of the most important chart in the world) has been measuring how long frontier models can autonomously handle multi-step tasks. They calibrate their benchmarks against how long the same tasks take human experts, so the results are in units of time: a model "can handle 30 minute tasks" means it can reliably complete work that would take a skilled human about 30 minutes.
And the curve has been absurd. GPT-4 was around 4 minutes. Claude 3.5 Sonnet got to roughly 11. Claude 3.7 Sonnet reached about an hour. o3 got to around 2 hours. GPT-5 landed near 3.5 hours. The newest frontier models, like Claude Opus 4.6, are pushing toward 12 hours. That is roughly a 180x increase in autonomous task horizon in about two years, with METR measuring a doubling time of about 131 days since 2023.
Why does that matter for inference demand? Because longer task horizons do not just mean "the model is smarter," they mean the model can stay in the loop longer. A model that can only handle a 4 minute task might read a little context, take a couple actions, and stop. A model that can handle a 4 hour task can read, call tools, inspect outputs, revise its plan, and keep going until it completes a meaty task. Every additional loop means more context replay, more tool output, more intermediate state, and more reasoning. So as capability rises, tokens per task rise with it (often faster than linearly).
You can see this in concrete workloads. In customer support, a basic FAQ bot in 2023 might have consumed around 3,500 tokens for a ticket, better retrieval pushed that higher, then tool use and reasoning pushed it higher again, and now full voice support stacks are higher still. Coding follows the same pattern, just more violently: what used to be tens of thousands of tokens for a bounded coding task has become hundreds of thousands or even well over a million as agents became capable enough to handle real debugging, refactoring, and multi-file work. Each useful task now justifies much more inference than it did a year or two ago, because the model can actually finish the job.
This is a subtle version of Jevons paradox. The sticker price per token has actually been rising for frontier models, not falling. But the value per million tokens has gone up much faster: a frontier model today can complete a workflow in one coherent session that would have required dozens of brittle attempts a year ago, or simply could not have been done. Effective cost per useful outcome is dropping even as nominal cost per token climbs. And that dynamic is what opens up entirely new categories: complex insurance claims, broad code refactors, long-running research tasks, multi-step back-office processes. These were not meaningfully part of the inference market two years ago because the models could not stay coherent long enough to do them.
The aggregate numbers suggest this is already happening. OpenAI's API is processing more than 15B tokens per minute as of April 2026, up from 6B half a year earlier. Google went from 9.7T tokens per month to 480T in a year, about 50x growth. OpenAI says reasoning token consumption per enterprise organization grew 320x year over year. Anthropic's latest reported annualized revenue of $30B (up from $10B to start the year...) speaks for itself, especially given the main driver is Claude Code and their API.
This explosion is three curves compounding on top of each other: more users, more tasks per user being routed through models, and more tokens consumed per task as models can sustain longer, deeper workflows. If users double or triple, tasks per user also climb, and tokens per task rise again on top of that, total demand moves much faster than any one of those curves in isolation. Google's roughly 50x YoY token growth is what that kind of compounding looks like in the wild.
That is why I think the current market size still significantly understates where this goes. Even a conservative estimate puts today's market somewhere around 10T+ tokens per day across providers. In 2028 I think you're looking at 10x more tokens (in a base case). We are still early in a period where better models do not just win share from other models, but they are pulling entirely new workloads onto the inference grid.
How to Read the Map
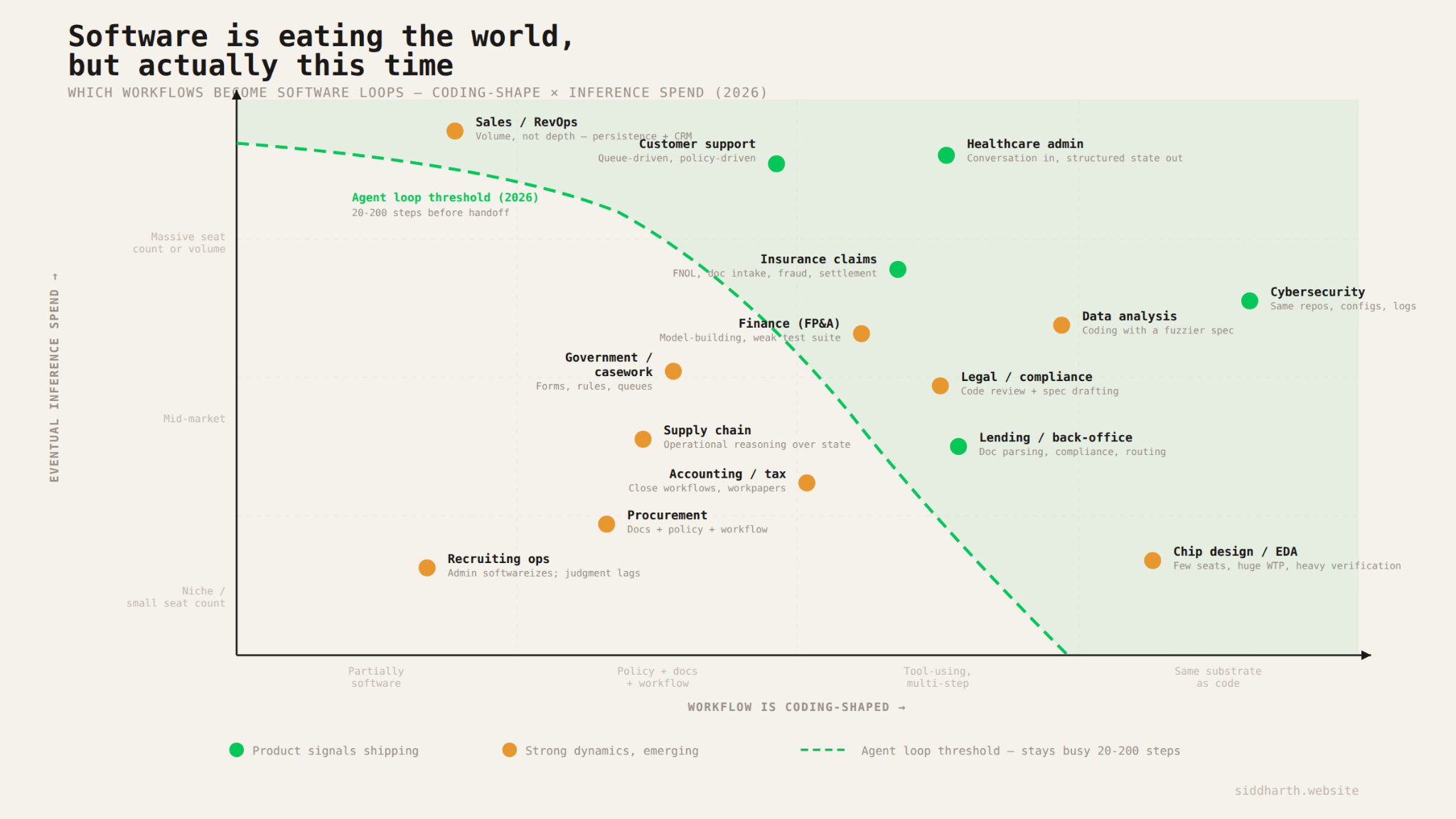
If you're trying to figure out where inference demand is heading in a specific industry, or evaluating a company that's building in one of these categories, I think there are really two questions worth asking about any workflow.
The first is how coding-shaped is it? Can an agent stay busy for 20 or more steps without a human needing to intervene? Are there tool calls involved, like database lookups or API requests or document retrieval? Can the agent verify its own work through some kind of digital check? The more coding-shaped a workflow is, the higher up the token ladder each task will sit, and the more inference it will burn per interaction.
The spectrum runs on a few things. How structured is the input? A mortgage application with standardized forms is more coding-shaped than a legal dispute with freeform depositions. How deterministic is the decision logic? Lending compliance checks have clear pass/fail rules; investment analysis involves judgment calls where reasonable people disagree. How clean is the verification? A record either updated correctly or it didn't, but "did this contract redline actually improve the deal?" requires a human to weigh in. The more structured the input, the more deterministic the logic, and the more digital the verification, the further right a workflow sits on the chart, and the deeper the agent loop can run before it needs a human.
The second is how much volume does it generate? How many tasks per day, how many interactions per year? The highest volume workflows drive the most aggregate demand even if each individual task is only moderately token intensive.
The most interesting opportunities sit where both of these are high. Healthcare admin, customer support, and insurance all have workflows that are deeply coding-shaped and operate at enormous scale. These are the biggest near-term inference markets, and there are already real products shipping with real usage numbers to prove it.
At the other end you have domains like chip design and formal verification, where the per-seat token intensity is enormous (these are some of the deepest agent loops in existence) but the total addressable user base is small. The willingness to pay is very high though, which makes them attractive in a different way.
And then there's the middle band of legal, finance, accounting, supply chain, and government work, where the dynamics are clearly strong but adoption is still earlier. These are the categories worth watching closely over the next couple of years, because the METR capability curve suggests that the models are about to get good enough to handle the kinds of multi-hour, judgment heavy workflows that these domains require.
The last thing I'd watch is who gets to live inside the loop. As models commoditize, the durable application companies will be the ones that see the real work: the tool calls, retries, escalations, corrections, and edge cases that never show up in a benchmark. That is where the system learns how a specific workflow actually runs, and where proprietary context starts to accumulate. Over time, the advantage is not just access to a model. It is knowing how this insurer handles claims, how this hospital works denials, how this codebase breaks, how this finance team closes. The apps that capture that messy operational data will be the ones that improve fastest and defend their position longest.
Inference Is Eating the World
Software ate distribution first. It gave every business a website, an app, a CRM, a checkout flow. But most of the actual work still lived in people: answering calls, reviewing claims, debugging systems, reconciling books, routing approvals, chasing exceptions.
What is changing now is that the work itself is becoming software. Software that can read, reason, call tools, verify, revise, and keep going. A support interaction becomes an agent loop. A claim becomes a sequence of model calls. A bug becomes a long-running system that reads code, runs tests, and iterates until it finds the fix.
That is what inference demand really measures. More and more of the economy is being pulled onto the token ladder and executed as code. Software ate the world once by mediating business through screens. It may eat much more of it this time by doing the work underneath.
Thanks to Kishen, Vik, and Sabina for helping me on this piece!