Background Agent Optimizations
Part of the AI Systems topic guide.
How caching, routing, and scheduling change when coding agents run off the critical path.
How do you make inference fast and cheap when you're running dozens or hundreds of coding agents concurrently?
Stripe is merging over a thousand PRs a week from their "Minions" — background coding agents built on a fork of Block's Goose. Ramp's "Inspect" agent, powered by OpenCode on Modal, now accounts for over half of all merged PRs across their frontend and backend repos. Block itself has 4,000 employees using Goose internally.
Background coding agents aren't just a research project anymore. They're production infrastructure at some of the best engineering orgs in the world. And the companies running them are starting to think about the next problem: how do you make inference fast and cheap when you're running dozens or hundreds of these agents concurrently?
This is a different problem than optimizing inference for chat. vLLM, TGI, and the rest of the serving stack are optimized for interactive use — low latency on individual requests, fast time-to-first-token, smooth streaming. But background agents have two properties that change the optimization landscape entirely:
- They don't need real-time responses. A background agent can tolerate a few extra seconds of latency if it means better throughput overall. Nobody's staring at a screen waiting for it to finish.
- You have client-side context that can inform scheduling. You know what workflow stage each agent is in, what task type it's running, what files it's working on. An inference server serving chat requests doesn't have any of this — it just sees a stream of anonymous requests.
These two properties unlock a class of optimizations that don't exist in the standard serving stack. I wanted to know how much they're actually worth. So I started building silly-goose — an experimental fork of Block's Goose with an orchestration layer on top of vLLM (Qwen2.5-Coder-32B-Instruct on a Modal A100). I tested 8 different optimizations and got real numbers on all of them.
Note on silly-goose: This is experimental and not production-ready. As you'll see below, several optimizations didn't pan out, and the ones that work require multiple concurrent agents to show benefits. I'm continuing to experiment, but wanted to share these findings now since they're relevant to anyone thinking about this problem space.
Cash Considerations
The test environment was a Modal A100 GPU running vLLM with Qwen2.5-Coder-32B-Instruct, real workloads, multiple runs per experiment. No simulated cache hits or mock latencies.
Baseline timing:
| Task Type | Latency |
|---|---|
| Simple queries | 3-5 seconds |
| Complex queries with code | 8-15 seconds |
| Test analysis | 5-10 seconds |
Token generation speed was roughly 20-30 tokens/second for a single request, with throughput scaling up automatically via vLLM's internal batching.
Cost baseline (Modal A100 pricing ~$3.50/hr):
| Metric | Value |
|---|---|
| Cost per GPU-hour | ~$3.50 |
| Avg requests/hour (mixed workload) | ~400-500 |
| Cost per request (baseline) | ~$0.007-0.009 |
| Cost per 10-turn agent task | ~$0.07-0.09 |
At scale (100 concurrent agents, 8 hours/day), baseline inference costs run ~$2,800/day or ~$84,000/month. The optimizations below translate to real dollar savings:
| Optimization | Speedup | Monthly Savings (at scale) |
|---|---|---|
| Priority Scheduling | 1.22x | ~$15,000 |
| Model Routing | 1.45x | ~$26,000 |
| Speculative Prefetch | 1.90x | ~$40,000 |
These are rough estimates — actual savings depend on workload mix, GPU utilization, and whether you're bottlenecked on latency or throughput. But the point stands: at scale, even modest speedups translate to significant cost reduction.
Results Summary
Here's how the 8 optimizations shook out:
| Optimization | Speedup | Verdict | Layer |
|---|---|---|---|
| Priority Scheduling | 1.22x | Works, but needs multiple agents | Orchestration |
| Model Routing | 1.45x | Works, but changes behavior | Orchestration |
| Semantic Caching | 5.42x | Works, but actually detrimental — see dedicated section | Orchestration |
| Request Batching | 1.01x | No benefit. vLLM already does this. | Orchestration |
| Speculative Prefetch (LLM) | 1.90x | Works for predictable workflows | Single Agent |
| Speculative Prefetch (files) | 1.00x | No benefit. SSD reads are instant. | Single Agent |
| Streaming Tool Execution | ? | Untested | Single Agent |
| Context Compression | 0.89x | Made things worse | Single Agent |
The pattern that jumped out: every optimization that worked required multiple agents running concurrently. The single-agent optimizations either didn't help or actively hurt performance. And the optimizations that worked were exactly the ones that exploited those two background-agent-specific properties: tolerance for non-uniform latency and client-side context about agent state.
Where the Optimizations Actually Live
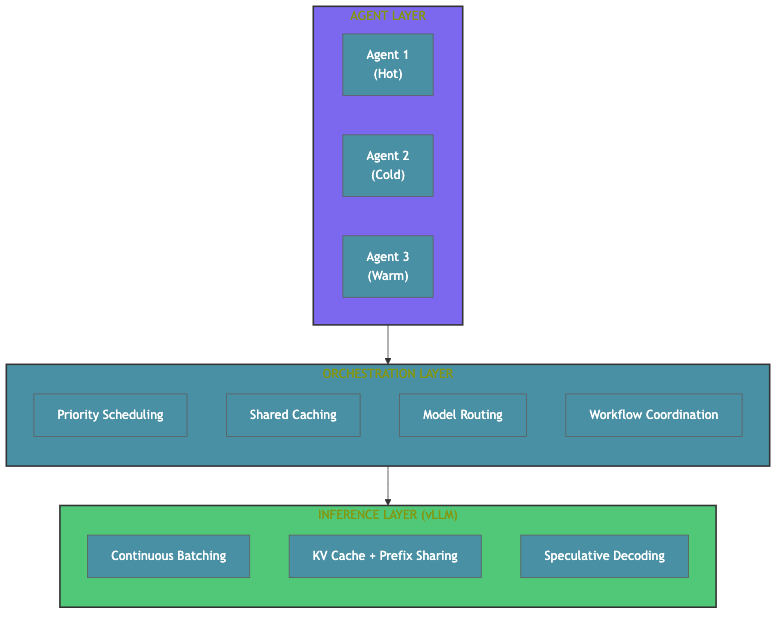
Almost everyone I talk to is thinking about optimizing the agent or the inference server. But the inference server is already good at what it was designed for — vLLM does continuous batching, KV caching, and prefix sharing out of the box. The problem is that it treats every request identically. It has no concept of "this agent is mid-debug and blocked" vs. "this agent just started exploring a codebase." It can't make scheduling decisions based on workflow state because it doesn't have that information.
The interesting work is in the middle. The orchestration layer is where you have visibility across agents, where you can make scheduling decisions based on client-side context, where you can exploit the fact that background agents don't need uniform latency. That's where the wins compound.
What Worked
Priority Scheduling (1.22x)
Background agents can report their workflow stage. An agent mid-debugging that's blocked waiting for a response ("hot") should get GPU priority over an agent that just started reading a codebase ("cold"). This is the kind of optimization that only makes sense when you're running multiple agents against the same GPU — which is exactly the scenario that matters at scale. And it only works because you have client-side context about what each agent is doing.

The implementation classifies workflow stage from the agent's recent messages and maps it to a priority tier:
pub enum AgentPriority {
Cold = 0, // Exploratory work, can wait
Warm = 1, // Active but not blocked
Hot = 2, // Mid-task, blocked waiting for response
}
pub enum WorkflowStage {
Explore, // Reading files, understanding codebase
Plan, // Planning approach
CodeEdit, // Actively editing code
TestAnalyze, // Running and analyzing tests
Docs, // Writing documentation
CommitMsg, // Creating commit messages
}
impl WorkflowStage {
pub fn priority(&self) -> AgentPriority {
match self {
Self::TestAnalyze | Self::CodeEdit => AgentPriority::Hot,
Self::Plan | Self::CommitMsg => AgentPriority::Warm,
Self::Explore | Self::Docs => AgentPriority::Cold,
}
}
}Classification is simple keyword matching on the last user message — "test" + "fail" maps to TestAnalyze, "fix" or "bug" maps to CodeEdit, etc. Not sophisticated, but it doesn't need to be. The scheduling uses semaphore pools: hot agents get up to 4 concurrent GPU slots, cold agents get up to 2, warm agents can use either pool.
Results:
| Metric | No Priority | With Priority | Change |
|---|---|---|---|
| Hot agent latency | 11,414 ms | 9,329 ms | -18% |
| Cold agent latency | 15,045 ms | 3,871 ms | -74% |
| Wall time | 22.33s | 19.83s | -11% |
Hot agents got ~18% faster, but the more interesting result is that cold agents got dramatically faster too (74% drop) because the queue cleared more efficiently overall. When hot agents finish faster, they release GPU slots sooner, which unblocks cold agents.
This is the optimization that most directly exploits the "background agents don't need uniform latency" property. You're explicitly saying: cold agents can wait. In an interactive chat setting, you can't do this — every user expects the same response time. With background agents, deliberately deprioritizing exploratory work to speed up blocked work is a free lunch.
Caveat: This only works if you have multiple agents competing for the same GPU. A single agent has nothing to prioritize against.
Speculative Prefetching (1.90x)
Agent workflows are predictable. After an edit, the agent almost always runs tests. After tests fail, it almost always reads the failing file. If you know the next step, you can fire both LLM requests simultaneously and let vLLM batch them.

We modeled agent tool patterns as a Markov chain:
| After This Action | Predicted Next Action | Probability |
|---|---|---|
| Edit src file | Run tests | 50% |
| Edit src file | Read same file | 20% |
| Edit src file | Edit same file again | 15% |
| Test fails | Read source file | 35% |
| Test fails | Read test file | 25% |
| Test fails | Edit source (fix) | 25% |
Prediction accuracy landed around 42%, which sounds low, but the win comes from the cases where you're right:
| Mode | Total Time |
|---|---|
| Sequential | 13.60s |
| Parallel (speculative) | 7.17s |
When both requests fire simultaneously, vLLM batches them efficiently and the wall clock drops nearly in half. When the speculation is wrong, you just discard the prefetched result — the cost is wasted GPU compute, not wasted wall time.
The GPU Contention Problem
There's a subtlety here that most discussions of speculative execution ignore. Prefetching only helps when there's spare GPU capacity:

| GPU Slots | Speedup | Notes |
|---|---|---|
| 2 | 0.79x | Worse — prefetches compete for scarce GPU |
| 4 | 0.98x | Neutral |
| 8 | 1.12x | Better — spare capacity available |
With high contention, prefetches make things worse by stealing slots from real requests. We prototyped an "opportunistic" mode using non-blocking try_acquire on the GPU semaphore — only prefetch when there's idle capacity. This avoids the contention problem but limits when prefetching can actually happen.
Bottom line: You need to decide whether your deployment has enough spare GPU headroom for speculative work. If you're running your GPUs at 90%+ utilization, prefetching will hurt more than it helps.
Model Routing (1.45x)
Not all tasks need the biggest model. Docstrings and commit messages don't need 32B parameters. Route simple tasks to 7B, complex debugging to 32B.

Task classification was keyword matching:
- Complex (→ 32B): "fix", "debug", "refactor", "implement"
- Simple (→ 7B): "docstring", "documentation", "commit message", "summarize"
Results:
| Metric | All 32B | Smart Routing | Change |
|---|---|---|---|
| Wall time | 21.71s | 15.00s | -31% |
| Avg latency | 11,850 ms | 8,005 ms | -32% |
| Simple task latency | 8,297 ms | 2,703 ms | -67% |
| Complex task latency | 11,451 ms | 7,729 ms | -33% |
Simple tasks completed 3x faster on 7B, and because they cleared the GPU queue faster, complex tasks benefited too. The wall time dropped from 21.7s to 15.0s — a bigger system-level impact than the per-request numbers suggest, because faster simple tasks free up GPU capacity for the complex ones.
This is another optimization that relies on client-side context. The proxy knows the task type because the orchestration layer classified it. A generic inference server would need the client to pass this metadata explicitly.
Note: This is mostly a product decision, not a technical one. Many users just want the best model on everything and will pay the additional cost (we see this with other coding agents where people almost always upgrade to the newest models once available regardless of cose). But if you're running a fleet of background agents and optimizing for cost/throughput rather than peak quality on every request, routing is a clear win.
Semantic Caching
The pitch for semantic caching is compelling: cache LLM responses, return cached results for semantically similar queries, and save on latency and cost. We saw an actual 5.42x latency speed up with semantic caching in our experiments! For chatbots, this works, but for coding agents, it's actively detrimental.
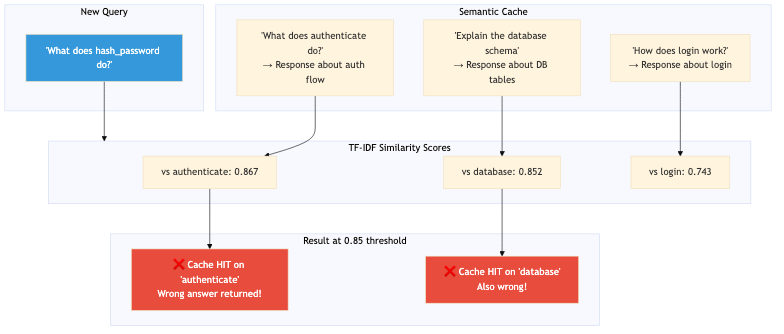
The False Positive Problem
Code analysis questions share vocabulary in ways that fool similarity metrics. Here are actual similarity scores we observed with TF-IDF embeddings:
| Query 1 | Query 2 | Similarity |
|---|---|---|
| "What does authenticate do?" | "How does the authenticate method work?" | 0.977 |
| "What does authenticate do?" | "Describe how authenticate works" | 0.870 |
| "What does authenticate do?" | "Explain authenticate function" | 0.867 |
| "What does hash_password do?" | "Explain the database schema" | 0.852 |
That last pair shows why this is a real issue. Completely different questions, but they share structural patterns ("What does / Explain the", function-like words, ".py" references). At a 0.85 similarity threshold (which you need for reasonable recall) they match. 90% of our cache hits were false positives.
What We Tried
| Approach | Hit Rate | Result |
|---|---|---|
| TF-IDF @ 0.85 threshold | 90% | Most hits were wrong |
| TF-IDF + file context @ 0.92 | 30% | Still risky |
| sentence-transformers (MiniLM) | - | Better, but needs domain tuning |
We could have kept tuning with better embeddings, file names in cache keys, per-query-type thresholds, cache invalidation on code changes, but we realized the fundamental problem isn't the similarity metric.
Error Propagation
In a chatbot, a wrong cached answer is annoying. In an agent, it's catastrophic.
When a chatbot returns a slightly wrong answer, the human reads it, thinks "that doesn't seem right," and asks a follow-up. The error is caught and corrected in the same turn.
When a coding agent gets a wrong cached answer about what a function does, it acts on that wrong information. It edits the wrong file. It writes code that calls a function incorrectly. It breaks tests for reasons that have nothing to do with the actual task. The error propagates through multiple tool calls before anyone notices — and by then, the agent has made a mess.
agentic workloads have fundamentally different error dynamics than interactive ones. Techniques that work fine for chat (where humans are in the loop catching mistakes) become dangerous when an autonomous agent takes the wrong information and runs with it.
When Caching Might Work for Agents
We killed semantic caching entirely, but there are narrow cases where it could work:
- Exact match caching — Same prompt, same response. No similarity matching. This is safe but has low hit rates. But this is also solved by prefix-caching and smart KV caches on the infra / host side.
- Caching tool outputs, not LLM responses — File reads, test results, grep outputs. These are deterministic and safe to cache (with invalidation on file changes).
- Caching with human verification — Flag uncertain matches for human review before using. Defeats the latency benefit but might work for async workflows.
- Task-specific caching — Some agent tasks (commit message generation, docstring writing) are more tolerant of approximate answers. Cache those, not debugging queries.
For now, we're not caching LLM responses at all. The risk/reward math doesn't work for coding agents.
What Didn't Work
Request Batching (1.01x — No Benefit)
My assumption was that collecting requests over a time window and sending them as a batch would improve throughput. I tested accumulation windows of 200ms and 1000ms.
| Mode | Wall Time | Avg Latency | Throughput | Batch Size |
|---|---|---|---|---|
| Passthrough | 21.34s | 11,878 ms | 20.3 tps | 1.0 |
| 200ms window | 20.96s | 11,704 ms | 19.3 tps | 5.5 |
| 1000ms window | 23.71s | 12,628 ms | 18.5 tps | 10.0 |
Higher batch sizes (5.5, 10.0) didn't improve throughput because vLLM's continuous batching already handles this. Requests that arrive at any time get dynamically added to the current batch — that's the whole point of continuous batching. All my accumulation layer did was add 200-1000ms of delay for zero benefit and slightly worse throughput.
We thought we could be clever here, but learned that we should not try and re-implement what the inference server already does. This one seems obvious in hindsight, but I've seen this mistake in multiple production systems. If you're adding a pure batching layer on top of vLLM, stop.
File Prefetching (1.00x — Nothing to Save)
While the agent waits for pytest, prefetch files it will likely read next. Prediction accuracy was 42%. Wall time improvement: 0%.
We should have profiled before we optimized. I assumed file I/O was slow. It wasn't. SSD reads are 10-50ms. The bottleneck was never there.
Context Compression (0.89x — Made It Worse)
Summarize code context to reduce prompt tokens. 80% fewer tokens. Result: 11% slower.
| Mode | Avg Latency | Prompt Tokens |
|---|---|---|
| Full context | 7,029 ms | 494 |
| Compressed | 7,920 ms | 97 |
Why? For a 100-token output:
- Prefill (processing the prompt): ~100-500ms
- Generation (producing the output): ~2,000-5,000ms
Generation dominates. Cutting prompt tokens saves prefill time, which is a small fraction of total latency. And you're potentially degrading response quality by summarizing away details the model might need.
Note: This result may not hold for very large contexts (10k+ tokens), where prefill becomes a bigger fraction of total latency. But for the prompt sizes typical of coding agent tasks (a few hundred to a couple thousand tokens), compression is a net negative.
Two Paths Forward
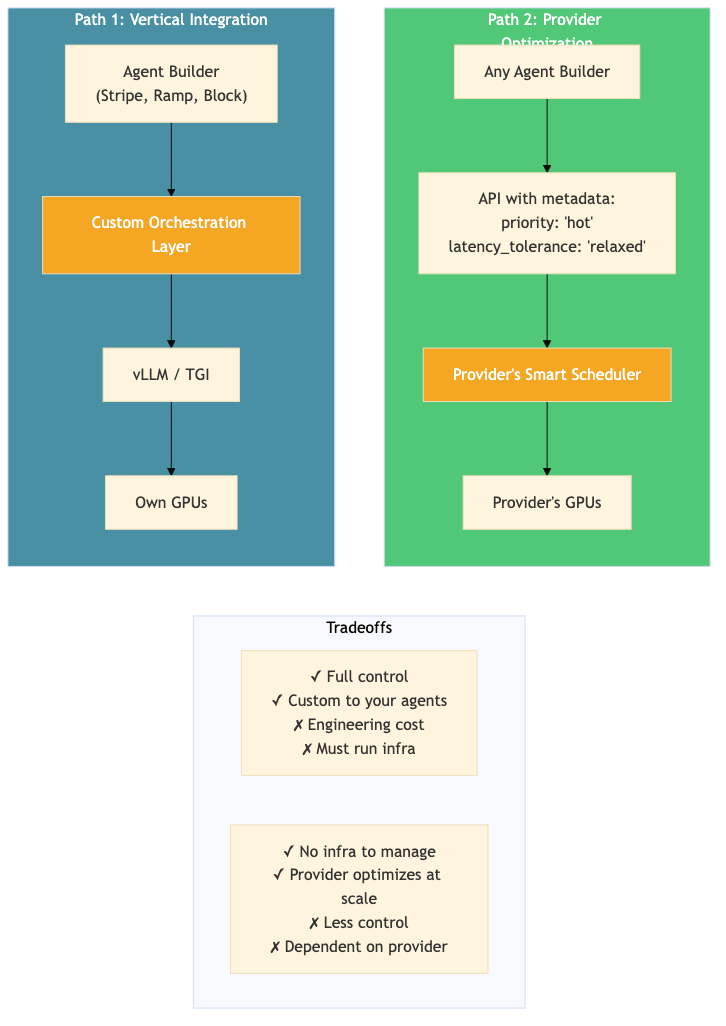
Path 1: Vertical Integration (for Agent Builders)
If you're building background agents and want to control the compute layer (the way Stripe, Ramp, and Block are effectively doing) you can get significant gains from an orchestration layer that sits between your agents and your inference server.
What you can do:
- Priority scheduling based on workflow stage
- Speculative execution for predictable patterns
- Model routing by task complexity
- Shared context across agents working on the same codebase
These are all optimizations that require owning both the agent and the scheduling layer. silly-goose is my proof of concept of this approach — and even with simple implementations (keyword-based classification, Markov chain predictions), the gains are real: 1.2-1.9x on individual optimizations, and they compound when you stack them.
silly-goose isn't production-ready yet (which is why I didn't even link the repo). Some optimizations (semantic caching) turned out to be dangerous, others (request batching) were redundant with what vLLM already does. But the experiments validated the core thesis: there are real wins available in the orchestration layer for anyone willing to build it.
This is the path for teams that are already running agents at scale and are hitting cost or throughput ceilings. You don't need to build your own inference server — vLLM is great — but you do need a layer on top of it that understands your agents.
Path 2: Provider Optimization (for Inference Providers)
The other path is for pure inference providers (the Fireworks, Togethers, Modals of the world) to build first-class support for background agent workloads.
Today, their APIs are optimized for chat: every request gets the same priority, the same latency target, the same treatment. But if they collected more metadata from the client side (workflow stage, task type, latency tolerance, agent identity) they could offer background-agent-specific scheduling as a service.
Imagine an API like:
{
"model": "qwen-32b",
"messages": [...],
"priority": "hot",
"latency_tolerance": "relaxed",
"agent_id": "agent-42"
}This is the same optimization as Path 1, just with a different division of labor. Instead of the agent builder running their own orchestration layer, the inference provider builds it into their serving stack.
| Path 1: Vertical | Path 2: Provider | |
|---|---|---|
| Control | Full control over scheduling | Limited to provider's options |
| Engineering cost | Build & maintain orchestration | Just pass metadata |
| Infrastructure | Run your own GPUs | Provider handles it |
| Customization | Tuned to your agents | Generic across customers |
I think both paths will play out. The Stripes and Ramps of the world will keep vertically integrating because they have the scale and engineering depth to justify it. But for the long tail of companies running background agents, inference providers who build background-agent-aware scheduling will have a real differentiator.