The App Layer Is Dead. Long Live the App Layer.
Part of the AI Systems topic guide.
Software ate the world in the 2010s, and now in the 2020s inference is eating the rest. The app layer is now dead.
The only question anyone in San Francisco is asking right now: if frontier models can stay coherent for 16 hours, run 30 sub-agents at once, and execute production workflows end to end, where is there room for an application company at all? (followed closely by: can the Giants score more than 1 run per game this season?)
Even if companies don’t want to vibe code their own CRM, application companies are getting attacked from every direction: the labs can bundle with their products, 50 YC companies probably started something similar last week, and if the cost of code is really going to 0, maybe DoorDash throws in a lightweight CRM as an add on with your team lunch order.
The products most obviously under attack are the ones that look like this: task boards, meeting notes, lightweight CRMs, internal tools, dashboards, onboarding flows, QA scripts, support macros, status reports, analytics summaries, content calendars, knowledge bases, and maybe half the things currently described as “workflow automation.”
The common feature of all these products is not that they are useless. Obviously most of them are very useful! The common feature though is that the work is bounded. You can describe the job in a sentence, rebuild the core loop in a weekend, and imagine the model doing most of the work without the application needing to become much deeper. "Summarize this meeting." "Turn this conversation into a ticket." "Generate a dashboard from these tables." "Track the status of these tasks." This is all real work, but if the job is bounded enough, the model eventually eats into the application's surface area until the app becomes mostly a wrapper around the model.
So what kind of app becomes more valuable as models get better? Or put differently, what can the application layer do that the model layer does not naturally do itself?
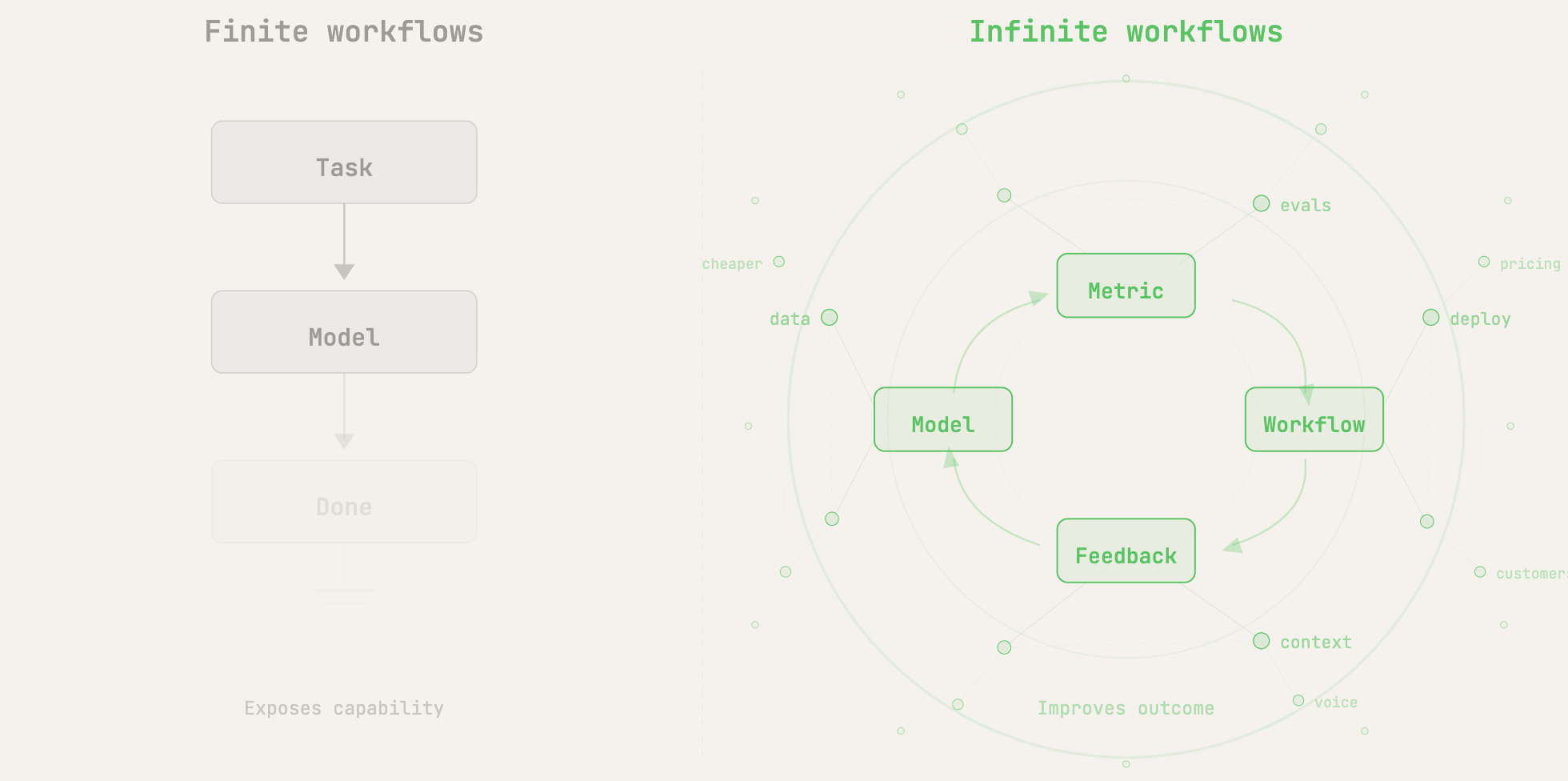
Application companies will win by owning a metric the customer cannot stop caring about: faster resolution, lower cost, higher conversion, fewer losses, more throughput. The job is not to be a better interface to a model, but rather to take general model capability and turn it into a measurably better outcome on a number the customer already tracks. Everything else (the UX, the domain knowledge, the “proprietary workflows,” whatever that means) is downstream of that.
The app companies that will work are not wrappers around models. They will be systems wrapped around metrics. A wrapper exposes a capability, but a product takes that capability and makes it show up in a number the customer already tracks. That is where the data, workflow, feedback loops, integrations, evals, and deployment model matter. A thin interface to a model gets eaten. A system wrapped around a metric has a chance.
The models are incredibly powerful, but they do not automatically know what the customer is trying to optimize. The model does not own the workflow. It does not see the feedback loop. It does not necessarily have access to the operational context, does not know which errors are acceptable and which are fatal, and does not know where the metric actually bends or breaks. The model makes the work cheaper, and the application has to turn cheaper work into better measured outcomes.
History must be Tupac the way it rhymes
Before 1979, financial modeling was physical labor disguised as intellectual labor. An analyst built a model by hand, in pencil, on green columnar paper. Changing an assumption meant rerunning the math. A mistake on line 47 could poison line 213. The cost of one model was high enough that most possible models simply never got built. Then VisiCalc arrived, followed by Lotus 1-2-3, then Excel, and the cost of running the next model collapsed.
The obvious prediction was that analysts would become less necessary. If the spreadsheet does the arithmetic, why pay armies of junior people to crunch numbers? But that is not what happened. One model became twenty. Sensitivity tables, DCFs, LBOs, merger models, downside cases, upside cases, and the cursed tab no one is allowed to touch because the whole workbook breaks if you breathe on it wrong.
The metric the bank cared about did not change. It was still something like "did we win the mandate, did the partner trust the analysis, did the deal close at the price we modeled." The spreadsheet did not solve that metric. It raised the ceiling on how good you could get at it. A pencil and paper analyst could build one base case. A spreadsheet enabled analyst could pressure test a hundred. The bank that took the new capability and ran further with it on the same metric won more mandates than the bank that did not. Forty years later, analysts are still chasing the same metric, with more compute and better tools and more data, and the ceiling has still not arrived.
The older case is even cleaner. "Computer" used to be a job title: a person paid to do calculations by hand, producing ballistics tables, census tabulations, payroll calculations, scientific tables. Mechanical and then digital computers automated the job almost completely. If you were a human computer, this was bad news. If you were the economy, it was the beginning of the modern era.
Automated computation did not reduce demand for computation. It made computation so cheap that entirely new categories became possible: aircraft simulation, genome sequencing, weather prediction, real-time auctions, cryptography, search, neural networks. But more importantly, it changed what "good" meant on every existing quantitative problem. Pre-computer, "accurate to the third decimal" was a heroic effort. Post-computer, it is the floor. Every quantitative metric (error rates, latency, throughput, precision) got a permanent ceiling lift, and every field that ran on those metrics spent the next several decades chasing the new ceiling. None of them have stopped chasing it.
Cheaper unit cost of intellectual labor does not solve the metrics customers care about. It raises the ceiling on how good those metrics can get, and the customer's appetite for "better" does not asymptote. Make calculation cheaper, and the world calculates more, and the world demands more accurate calculation than it did before. Make modeling cheaper, and the world models more, and the world demands tighter models than it did before. Make code cheaper, and the world will not write the same amount of software for less money. It will demand software that performs better on every metric the old software was already being measured on, and that is when software truly eats the world.
This is the part all the bears keep missing. They look at the metrics that current SaaS companies hit (30% support resolution, 60% click through rates, 3 day procurement cycles) and assume those numbers are what the customer wants. They are not. They are what the customer has settled for, given the cost of doing better. When the cost floor drops, the numbers people settle for stop being acceptable, and the company that takes the new capability and pushes the metric harder is the company that wins.
Some software will be eaten because the metric it owns has already saturated and there is nowhere left to push, and some software will eat through the floor because the metric it owns has no asymptote and the customer will keep paying to climb.
Hill Climbing
Customer support feels like the most obvious thing for the models to eat. A customer asks a question, the model reads the help center, gives an answer, maybe cites the right policy. Useful, but not exactly a company. And if that were the whole product, it would not be one. OpenAI could ship it tomorrow (and probably will).
The honest version of the "what about the labs" question has four layers.
The first is what the labs will absolutely ship and do reasonably well. A frontier lab can build a generic agent that ingests a help center, plugs into Zendesk or Intercom, calls a refund API, measures reply sentiment as a CSAT proxy, and handles roughly 30-40% of typical FAQ type tickets out of the box. That product will exist, it will be fine, and it will be free or near-free bundled with your API spend. For small businesses, startup support functions, and any team where "better than nothing" is the bar, the lab wins. This is what gets eaten by the models on the application software buffet.
The second is what a specialist does that the labs could do but probably won't. A serious support product has to know the shape of a specific customer's CRM, their internal escalation paths, their tier-3 engineers' Slack channels, their refund policy edge cases, their fraud team's escalation criteria, their billing system's actual quirks, etc. None of this is technically out of reach for the labs. The reason they will not close this gap is attention allocation. The marginal lab engineer is always more valuable on capability that generalizes across a thousand customers than on the specific way one company handles dunning. A determined lab with a deployment arm could chip away at this, but slowly, and only for their largest accounts. The middle of the market gets left to specialists by default.
The third is what the labs will not do, even though they obviously can. Claude Code and Codex prove that frontier labs can build products that capture deep customer specific context like entire codebases, internal libraries, deploy infrastructure, team conventions, but coding is special to the labs because it loops back into their own self-improvement. Every improvement to Claude Code makes Anthropic measurably better at building Anthropic. Every improvement to Codex makes OpenAI measurably better at building OpenAI. The marginal engineering hour spent making coding agents more capable returns to the lab not just as product revenue but as compounding capability inside the lab itself. That is why the labs are willing to commit absurd engineering depth here.
Support (and other apps) does not loop back this way. Anthropic does not get measurably better at being Anthropic by getting better at resolving Stripe's billing tickets. Neither does OpenAI. The work of going from 40% to 80% resolution at one specific company is valuable work, but the returns from doing it accrue almost entirely to the customer, not to the lab's model. The lab's central economic question is "what makes our model more capable," not "what makes one customer's support function more efficient," and the answers to those two questions point at different engineering investments.
This is the actual structural reason labs leave the middle and top of vertical markets on the table. Not because they cannot go deep (they obviously can if they wanted to) but because going deep in a vertical that does not loop back into their own self-improvement competes for engineering attention against verticals that do. Coding wins that comparison every time.
The result is an asymmetry. The labs will go absurdly deep in a narrow set of verticals (coding, evals, agent infrastructure, research workflows) anywhere their own improvement loops through customer use. They will stay shallow everywhere else, not because they cannot, but because the alternative use of the same engineering hours is more valuable to them. The specialist support company gets the middle and top of the support market by default because the lab has decided to build something else.
The fourth is organizational. A great support product is not just software. It is a relationship with the customer's support org. The application company sends deployment engineers who sit with the support team, runs weekly reviews of escalations, catches when the agent is misclassifying a new category of issue, fine-tunes the policy logic when the company changes its refund rules, and ships product changes against feedback the customer would not have known how to file as a bug. The application company prices on outcomes (resolved tickets, deflection rate, cost saved) rather than tokens consumed. None of this is impossible for a lab to do, but it is all a different shape of company than a lab is. The labs sell tokens at scale, and their economics are organized around tokens. The application company sells resolved tickets to a small number of customers, and its economics are organized around the outcome. Forcing a lab into outcome-based pricing for support specifically would cannibalize its primary business.
The labs will own the bottom of the market, where free is good enough and 30% resolution clears the bar. Application companies will own the middle and top, where the buyer is paying for the gap between generic automation and specific outcomes: 70% resolution with acceptable CSAT, clean escalations, lower cost per ticket, faster time to resolution. That gap is the company, and it keeps widening, because once the product owns one slice of the support function, the customer immediately wants the next one: refunds, subscription changes, account-specific troubleshooting, multi-turn complaints, proactive outreach, voice, and eventually the edge cases that used to live in the head of the support rep who had been there for seven years.
In short, (3) and (4) above are just comparative advantage from Econ 101. A lab may be better than a support startup at almost every underlying technical task: model quality, infra, agents, evals, deployment, etc., but that does not mean the lab should do the support startup’s job. The lab’s scarce resource is attention (like all of us), and every hour spent learning the weird escalation paths of one company’s support org is an hour not spent on model capability, coding agents, research workflows, or infrastructure that compounds across the whole customer base. The specialist wins not because the lab cannot do the work, but because the work is worth more to the specialist than it is to the lab.
The pattern is not new. Meta is the cleanest mature example of an infinite application surface, and it is worth one paragraph because it shows the dynamic survives at scale.
Advertisers do not buy Meta because they love Ads Manager. They buy Meta because Meta produces outcomes: purchases, leads, installs, ROAS, CAC, LTV. The entire product is a machine for making the next advertising dollar perform better, and the question it answers has no ceiling: can Meta find more of the people who are likely to buy, at a price that makes the advertiser money? Every part of the product (targeting, ranking, creative optimization, auctions, conversion tracking, lookalikes, attribution, budget pacing, signal recovery after ATT, Advantage+) is in service of that one question. The more spend flows through, the more the system sees. The more it sees, the better it gets. The better it gets, the more spend it earns. Meta owns the loop around the outcome advertisers care about, and that ownership is why the product compounds even when individual capabilities commoditize.
The same shape, 20 years later, is what the next generation of application companies will build. Support, sales, IT, claims, fraud, lending, content moderation, etc. Basically anywhere a metric the customer cannot stop caring about can be owned end-to-end by a specialist who climbs the quality frontier faster than the customer can climb it alone (even with all the AI tools in the world).
Long live the app layer
The phrase "vertical AI" feels both right and wrong. Right because the application company usually needs domain depth (context, workflow, data, evals, integrations, taste), but wrong because it can make the company sound defensible merely for having picked a vertical.
"AI for finance" is not a moat. "AI for legal" is not a moat. "AI for healthcare" is not a moat. The moat is not the noun after "AI for." The moat is the ability to keep improving a metric the customer cannot stop caring about, faster than the customer can improve it with a model alone.
If the product does not improve the metric much more than the generic model, it gets eaten. If the product improves the metric a little today but has no path to keep improving it tomorrow, it gets commoditized. But if the product owns the workflow, sees the feedback, measures the outcome, and keeps pushing the quality frontier forward, then every model improvement helps it. The lab ships a better model and the product gets better. The model gets cheaper and the product can run more workflows. The context window grows and the product can handle more complex cases. Tool use improves and the product can complete more work. The same force that kills the wrapper strengthens the system.
The last generation of great software companies captured workflows and defended them with distribution. The next generation will capture metrics and defend them with compounding quality loops. They will start by doing the obvious thing (like answer the support ticket, resolve the IT request, generate the ad, draft the contract, review the claim, investigate the alert) and then they will keep going. They will use every new model improvement, every customer interaction, every edge case, every integration, and every deployment to push the metric further.
That is the infinite game inside the app layer: the product surface grows with the customer’s appetite for a better number.
The app layer is dead if the app is a bounded wrapper around a model, but the app layer is very much alive if the app applies model capability to drive a better metric.
The model can do the task. The company has to improve the outcome.
Long live the app layer.
Thank you to Vik, Max, and Kishen for the help on this piece!